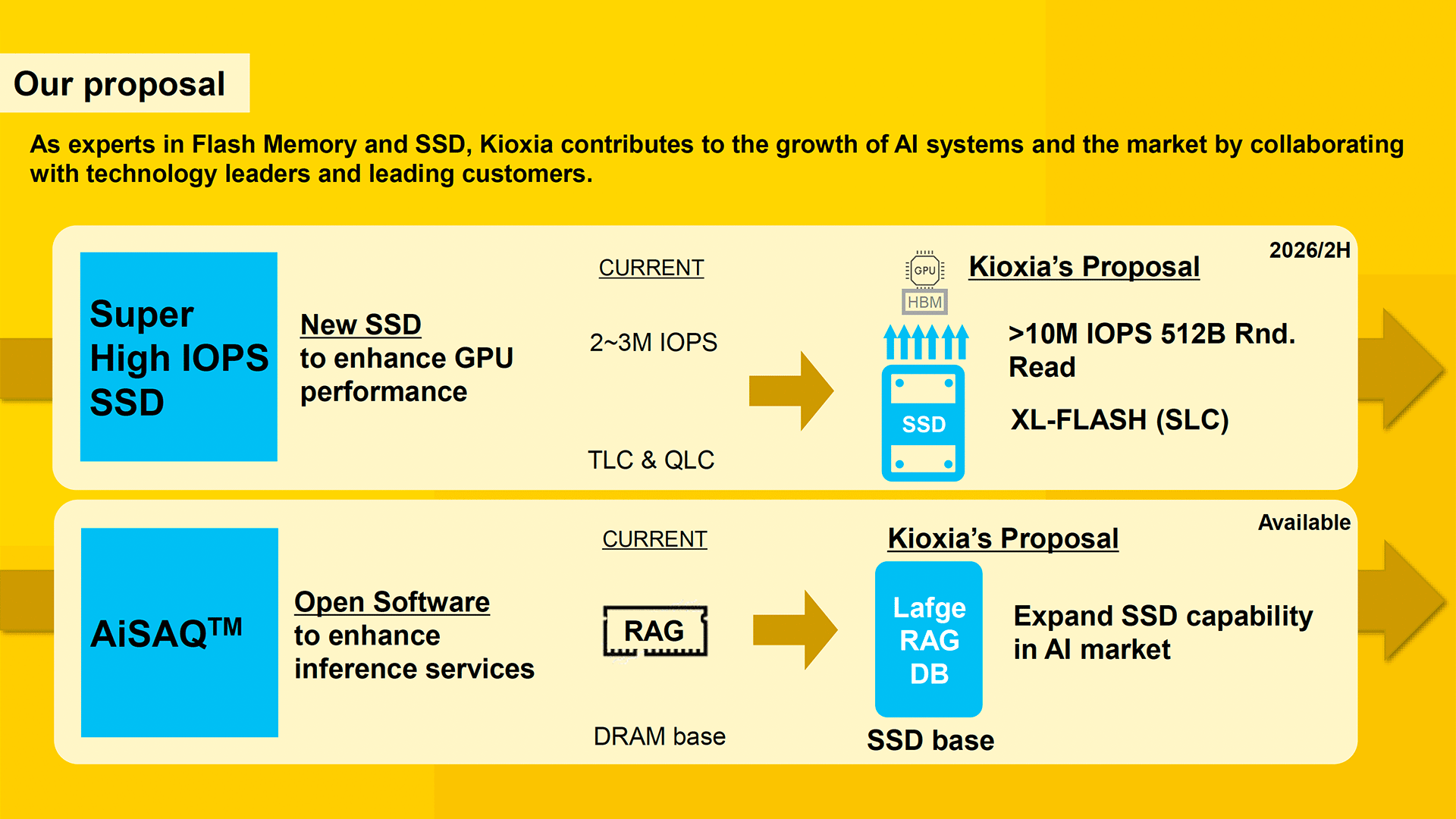
Kioxia chuẩn bị ra mắt ổ SSD XL-Flash nhanh gấp 3 lần bất kỳ ổ SSD nào hiện nay — đạt 10 triệu IOPS và kết nối trực tiếp với GPU dành cho máy chủ AI
Kioxia đang chuẩn bị thay đổi toàn bộ cách tiếp cận lưu trữ với một mẫu SSD mới, được thiết kế để vượt mốc 10 triệu IOPS (input/output operations per second) trong các tác vụ xử lý khối dữ liệu nhỏ — nhanh gấp 3 lần nhiều ổ SSD hiện đại hiện nay. Công ty đã tiết lộ thông tin này tại cuộc họp Chiến lược Doanh nghiệp gần đây.
Một trong những điểm nghẽn hiệu suất chính của các máy chủ AI hiện nay là việc truyền dữ liệu giữa bộ lưu trữ và GPU, vốn thường phải đi qua CPU, gây ra độ trễ và thời gian truy cập kéo dài.
Để đạt được mục tiêu hiệu suất, Kioxia đang phát triển một bộ điều khiển (controller) mới được tối ưu hóa cho IOPS cao — vượt ngưỡng 10 triệu IOPS với khối 512 byte — cho phép GPU truy xuất dữ liệu ở tốc độ đủ để duy trì 100% hiệu suất lõi xử lý.
Mẫu "AI SSD" này sẽ sử dụng bộ nhớ XL-Flash dạng SLC (single-level cell) của Kioxia, với độ trễ đọc chỉ từ 3–5 micro giây, thấp hơn nhiều so với độ trễ 40–100 micro giây của các SSD sử dụng 3D NAND thông thường. Ngoài ra, việc lưu trữ 1 bit mỗi cell giúp truy cập nhanh hơn và độ bền cao hơn — rất phù hợp cho khối lượng công việc AI yêu cầu cao.
Trong khi các SSD trung tâm dữ liệu cao cấp hiện tại đạt khoảng 2–3 triệu IOPS với khối 4K hoặc 512B, thì các mô hình ngôn ngữ lớn (LLMs) và hệ thống RAG (retrieval-augmented generation) thường truy cập dữ liệu nhỏ và ngẫu nhiên, như embeddings hay tham số mô hình. Vì vậy, khối 512 byte phù hợp hơn với thực tế hoạt động của AI so với khối 4K.

Điều đáng chú ý là Kioxia vẫn chưa tiết lộ ổ SSD này sử dụng giao diện kết nối nào, nhưng có vẻ không cần đến PCIe 6.0 về mặt băng thông.
Ổ AI SSD còn được tối ưu hóa cho giao tiếp peer-to-peer giữa GPU và SSD — bỏ qua CPU — để đạt hiệu năng cao hơn và độ trễ thấp hơn. Điều này cũng lý giải vì sao Kioxia (và cả Nvidia) chọn khối 512B, vì GPU vốn xử lý dữ liệu theo cache line nhỏ (32, 64 hoặc 128 byte) và cần truy cập liên tục nhiều vị trí bộ nhớ nhỏ để giữ các lõi xử lý luôn hoạt động.
SSD này được thiết kế dành cho đào tạo mô hình AI, đặc biệt là các mô hình ngôn ngữ lớn (LLMs) yêu cầu truy cập dữ liệu khổng lồ với tốc độ cao và liên tục. Đồng thời, nó cũng phù hợp với AI suy luận (inference), nơi mà các hệ thống sử dụng kỹ thuật RAG để tăng cường kết quả sinh với dữ liệu thời gian thực. Với các hệ thống như vậy, việc truy xuất bộ nhớ có độ trễ thấp và băng thông cao là điều bắt buộc để đảm bảo hiệu quả và phản hồi nhanh.
 Tin liên quan
Tin liên quan


 Sản phẩm mới
Sản phẩm mới









